When you inject new software into an environment, it’s difficult to forecast what will transpire.
Product teams continually try to predict what will work. We predict that a certain new feature will increase conversion, that a targeted ad spend will bring critical mass, or that market conditions will change in our favor. We expect many of our bets to fail.
We inoculate ourselves from bad predictions with methodologies like Agile and Lean Startup. Measuring market signal with each iteration helps us quickly change course. If the brilliant new feature decreases conversion, we can remove it before our revenue plummets.
Minimizing losses from bad bets give us more opportunities to try things. However, the experience of failed attempts does not reliably lead to better predictions in the future. Faced with new information, we can overreact, under-react, misunderstand, forget, or turn a blind eye. Emotions and cognitive biases can cloud our judgment.
Learning can go even more haywire at an organizational level. Add group-think, knowledge silos, and corporate amnesia to the list of epistemological threats.
But imagine if we could systematically improve the accuracy of our company’s predictions. Then we could reliably increase our ability to make winning bets over time.
I was surprised to discover that a playbook for optimizing prediction accuracy already exists. It’s called Superforecasting. But it’s not being widely leveraged by product teams yet.
Superforecasting
The first step to improving something is measuring it. In the book Superforecasting, Philip E. Tetlock and Dan Gardner describe a system for measuring the accuracy of predictions called the Brier score. In their words, “Brier scores measure the distance between what you forecast and what actually happened.”
To explain Brier scores, let’s consider weather forecasting.
Weather forecasting involves making probabilistic predictions like “There’s a 70% chance it will rain tomorrow.” If it doesn’t rain tomorrow, it doesn’t mean the forecast was wrong since it gave a 30% chance of no rain. This can be counter-intuitive since people have a false tendency to think that a forecast is wrong when a prediction that something is likely doesn’t end up happening.
In the terminology of the Brier score, a forecaster’s predictions are “well calibrated” if the things they say are X% likely to happen actually happen X% of the time. So if a meteorologist says “there’s 70% chance of rain tomorrow” one hundred times during the year, they would be perfectly calibrated if it rained 70 times and didn’t rain the other 30. If it had only rained 50 times, we would say the forecaster is over-confident. If it had rained 80 times, they’re under-confident. Over-confidence and under-confidence are the two forms of mis-calibration.
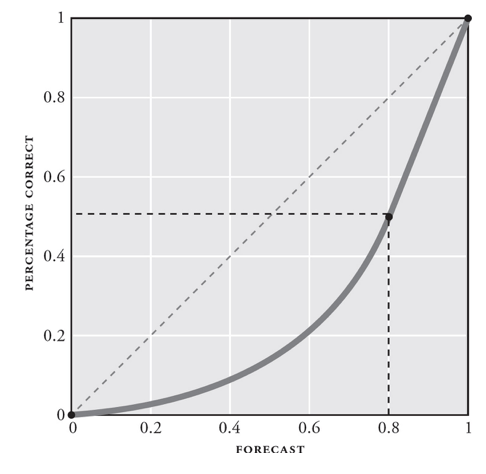


The other dimension of the Brier score is resolution. Resolution measures the decisiveness of a forecaster’s predictions. If a meteorologist says the chance of rain is 100% when it does rain and 0% when it doesn’t, they would have perfect resolution.
Forecasters can be perfectly calibrated with poor resolution. Let’s say a forecaster predicts a 50% chance of rain every day. Even if it does rain exactly half of the days, their resolution will be dinged for not elevating the chances on the days it does rain and lowering them on the days when it doesn’t. Poor resolution implies overly cautious predictions.
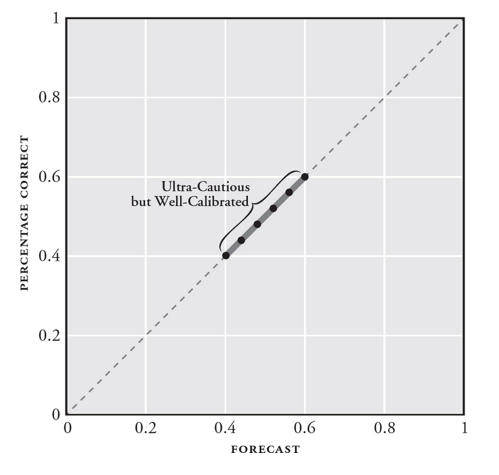

The Brier score combines calibration and resolution into a single accuracy metric. The lower the Brier score, the more accurate a forecaster’s predictions.
With a metric for prediction accuracy, we can scientifically investigate which factors lead individuals or teams to improve their foresight. Tetlock did exactly this to win a forecasting tournament administered by the United States Intelligence Community.
The forecasting tournament was created in the wake of the tragic false assessment that Iraq possessed WMDs. According to the IARPA website, the goal of the government program is to
… dramatically enhance the accuracy, precision, and timeliness of intelligence forecasts for a broad range of event types, through the development of advanced techniques that elicit, weight, and combine the judgments of many intelligence analysts.
The tournament, held over four years, asked participants to forecast questions like “Will Russia officially annex additional Ukrainian territory in the next three months?” and “In the next year, will any country withdraw from the eurozone?”
As measured by the Brier score, the predictions made by Tetlock’s group of “superforecasters” were 30% more accurate than the average for intelligence community analysts who has access to classified information.
While the highest performing forecasters are smart, Tetlock concluded that making consistently accurate predictions has more to do with how they think. Tetlock’s discoveries constitute a set of proven principles of good judgment, summarized here:
In philosophic outlook, [superforecasters] tend to be:
CAUTIOUS: Nothing is certain
HUMBLE: Reality is infinitely complex
NONDETERMINISTIC: What happens is not meant to be and does not have to happen
In their abilities and thinking styles, they tend to be:
ACTIVELY OPEN-MINDED: Beliefs are hypotheses to be tested, not treasures to be protected
INTELLIGENT AND KNOWLEDGEABLE, WITH A “NEED FOR COGNITION”: Intellectually curious, enjoy puzzles and mental challenges
REFLECTIVE: Introspective and self-critical
NUMERATE: Comfortable with numbers
In their methods of forecasting they tend to be:
PRAGMATIC: Not wedded to any idea or agenda
ANALYTICAL: Capable of stepping back from the tip-of-your-nose perspective and considering other views
DRAGONFLY-EYED: Value diverse views and synthesize them into their own
PROBABILISTIC: Judge using many grades of maybe
THOUGHTFUL UPDATERS: When facts change, they change their minds
GOOD INTUITIVE PSYCHOLOGISTS: Aware of the value of checking thinking for cognitive and emotional biases
In their work ethic, they tend to have:
A GROWTH MINDSET: Believe it’s possible to get better
GRIT: Determined to keep at it however long it takes
I love how Tetlock’s research puts data to philosophically rich concepts, like the hedgehog-fox dichotomy. The Ancient Greek poet Archilochus famously said that “a fox knows many things, but a hedgehog one important thing.” Tetlock categorized his forecasters into each persona.
Hedgehogs are fixated on one Big Idea; a single world view. They see everything through that lens. Tetlock describes this group in his forecasters pool:
Some were environmental doomsters (“ We’re running out of everything”); others were cornucopian boomsters (“ We can find cost-effective substitutes for everything”). Some were socialists (who favored state control of the commanding heights of the economy); others were free-market fundamentalists (who wanted to minimize regulation). As ideologically diverse as they were, they were united by the fact that their thinking was so ideological. They sought to squeeze complex problems into the preferred cause-effect templates and treated what did not fit as irrelevant distractions. Allergic to wishy-washy answers, they kept pushing their analyses to the limit (and then some), using terms like “furthermore” and “moreover” while piling up reasons why they were right and others wrong. As a result, they were unusually confident and likelier to declare things “impossible” or “certain.”
Foxes, in contrast, are open to many perspectives. They synthesize inputs from multiple models. Tetlock writes:
The [fox] group consisted of more pragmatic experts who drew on many analytical tools, with the choice of tool hinging on the particular problem they faced. These experts gathered as much information from as many sources as they could. When thinking, they often shifted mental gears, sprinkling their speech with transition markers such as “however,” “but,” “although,” and “on the other hand.” They talked about possibilities and probabilities, not certainties. And while no one likes to say “I was wrong,” these experts more readily admitted it and changed their minds.
The hedgehog vs. fox battle has been officially settled: foxes win, at least as far as forecasting goes. Tetlock found that “Foxes beat hedgehogs on both calibration and resolution. Foxes had real foresight. Hedgehogs didn’t.” Imagine an economist who relentlessly preaches austerity in the face of clear evidence showing the failure of austerity measures.
Yet, Tetlock doesn’t close the door on the utility of the hedgehog mindset. He raises the possibility that, while Hedgehogs suck at forecasting, their commitment to a single frame of thinking might lead them to ask more illuminating questions. Tetlock speculates:
The psychological recipe for the ideal superforecaster may prove to be quite different from that for the ideal superquestioner, as superb question generation often seems to accompany a hedgehog-like incisiveness and confidence that one has a Big Idea grasp of the deep drivers of an event. That’s quite a different mindset from the foxy eclecticism and sensitivity to uncertainty that characterizes superb forecasting.
This is a compelling hypothesis for how foxes and hedgehogs can collaborate to achieve great things.
Applying Superforecasting to Startups
Now that we’ve taken a quick tour of superforecasting, let’s consider how the system could be applied to product development.
Imagine your team at an eCommerce startup is finishing a project to redesign the checkout page. Right before you launch an A/B test with the new page, you pose the question:
“Will the purchase conversion rate of the new checkout page beat the current page by 10% for the 30 days after launch?”
Everyone on your team provides probabilistic forecasts ranging from 10% to 80%. The average prediction gives a 30% chance that the new page will increase conversion by 10%.
If you had seen these forecasts before you committed to doing the project, would you have moved forward with it?
It depends. Given the scale of your company, maybe a 30% chance to increase revenue by 10% is a good bet to make. But maybe other endeavors are more likely to succeed, so you start forecasting all proposed projects before you prioritize them.
And your forecasts need not be limited to the impact of potential projects. You can predict other factors related to the inner workings of your company, the technological landscape, or the market. Some examples:
“Will the engineering team finish refactoring our accounting system within two months of the project start date?”
“If we added 5 employees to the sales team in March, will our customer base grow by 20% by the end of the year?”
“Will the augmented/virtual reality market exceed $100 billion in revenue by 2020?”
“Will the word recognition accuracy rate of Google Voice reach 99% by the end of 2019?”
“Will the average health insurance deductible increase by 5% by the end of 2018?”
With accurate forecasts to questions like these, we’ll be more aware of our capabilities and steps ahead of the market. We’d have the foresight necessary for exceptional strategy.
One might argue that companies are already making forecasts in the form of cost-benefit analysis or financial models. But these formats are too ambiguous to help us improve our predictions over time. Tetlock and Gardner write:
The first step in learning what works in forecasting, and what doesn’t, is to judge forecasts, and to do that we can’t make assumptions about what the forecast means. We have to know. There can’t be any ambiguity about whether a forecast is accurate or not…
In cost-benefit analysis, you might forecast the impact of a project to be high. But what exactly does “high” mean? And in what time frame must the benefit occur? There are too many shades of gray. And maybe we’re two months after launch with little impact from the project. Does that mean the prediction is wrong or do we give it more time?
With a financial model, the projections will surely not be exactly right. So how can we determine if the model was correct? How close do the numbers need to be?
Cost-benefit analysis and financial models serve a real purpose, but they must be converted into unambiguous forecasts if we’re serious about improving our predictions over time.
So let’s say our company starts making a high quantity of unambiguous predictions. If we calculated our collective Brier score, we’d probably see that it leaves much to be desired.
Besides the fact that accurate forecasting is hard, I suspect many startup people are especially poor forecasters. There’s a hedgehoggy aspect of working on a product. It requires an almost irrational devotion to the product direction; a narrow lens that misses relevant opposing perspectives. We may be prone to overconfidence in predicting the success of product launches or improvement of their environmental conditions. Exuberant optimism is conducive to good work but runs counter to accurate forecasting.
Perhaps company staff is too biased to proficiently forecast their own future. The solution could be to insert 3rd party superforecasters into a company’s operations. It appears that Tetlock co-founded a commercial firm based on this idea. I’m compelled to try this out. In the future, asking questions of superforecasters could become ubiquitous, like running user tests or customer surveys. I anticipate there’d be some challenges in transferring domain knowledge, at least as far as some key questions are concerned. But this can be overcome.
But even without enlisting external superforecasters, applying the model is useful. These practices will be beneficial no matter what:
- Creating unambiguous hypotheses for projects
- Making predictions before you commit to resourcing
- Looping back to old predictions to judge their accuracy
Turning these practices into habits is the goal of my side-project, Double-Loop.
A good way to summarize the potential of the superforecasting model for product teams is that it nudges us to become more like foxhogs, a hybrid animal invented by Venkatesh Rao. He explains:
The net effect of this personality profile is that the foxhog can live in a highly uncertain environment, and be responsively engaged within it, yet create a high-certainty execution context.This ability to turn uncertainty into certainty is the key to … entrepreneurial effectiveness…
Accurate predictions are not a sufficient for success. You need to ask the right questions. This requires leaving no stone unturned while you push forward on a singular mission to achieve your product vision.

this is really awesome! I’ve been reading a lot of Tetlock and Taleb recently and ruminating about how to apply it to product development. this blog post seems exactly that!
LikeLiked by 1 person
Thanks Steven! It makes me happy to hear my post resonated with you.
LikeLike